Kubernetes
[NKS] Deployment 생성
uuuhhh
2022. 11. 13. 01:43
⚠️ NKS(Naver Kubernetes Service) 환경에서 진행하였습니다. ⚠️
▪︎ Deployment 생성
- 나에게 할당된 네임스페이스가 잘 있는지 확인한다.

- 네임스페이스에 deployment 생성 !

apiVersion: apps/v1
kind: Deployment
metadata:
name: cn-app-dpy
labels:
app: cn-app
spec:
replicas: 3
selector:
matchLabels:
app: cn-app
template:
metadata:
labels:
app: cn-app
spec:
containers:
- name: cn-app
image: uh2959/cn-action
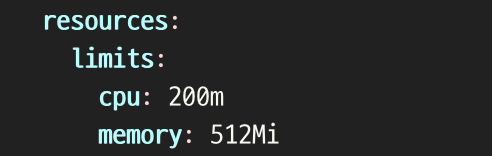
resources:
limits:
memory: "512Mi"
cpu: "500m"
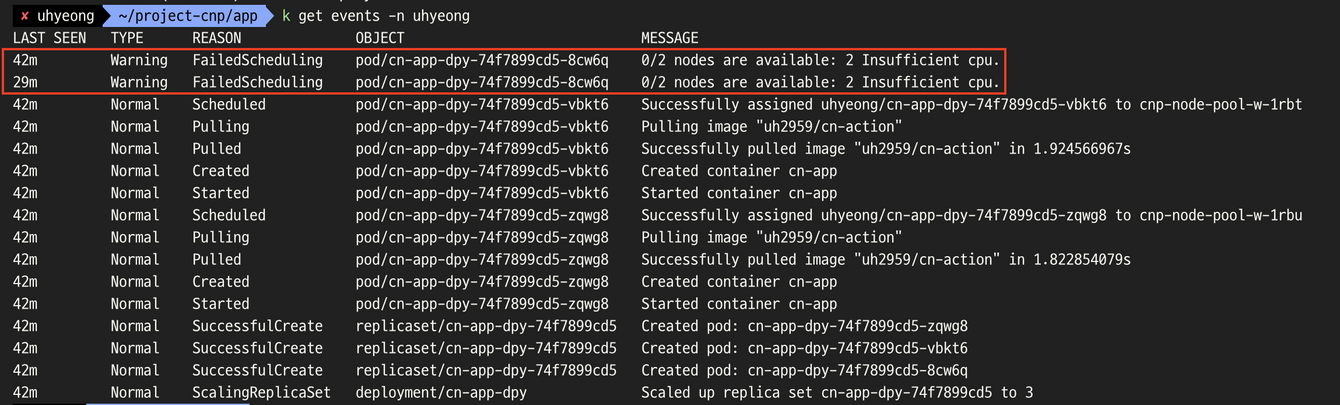
- 어라.. 왜 하나가 계속 pending이죠 ?

- 생성 과정 이벤트 로그를 확인해보자
- 0/2 nodes are availabe: 2 Insufficient cpu.
- 2개의 불충분한 cpu ??
▪︎ 트러블 슈팅
- 🚨 빨간불🚨키고 트러블 슈팅 들어갑시다 !
- 에러 메시지 그대로 cpu 자원이 부족하여 kubelet이 파드를 스케줄링을 하지 못해 FailedScheduling 에러가 발생한 듯하다.
- 누가 자원을 많이 먹고 있는지 확인할 수 있을까?
- 적절한 자원 요청을 어떻게 해줄 수 있을까?
- 특정한 리소스가 자원을 다 가져갈 수 없게 제한을 둘 수 있을까?
- 위와 같은 궁금한 것들이 생겨났고 일단 현재 이슈를 해결해보도록 하자
- 현재 리소스가 사용 중인 자원의 상황을 확인해보기
- 현재 사용 가능한 자원의 양을 확인해보기
- 과도한 자원을 사용 중인 리소스를 확인하여 자원 할당량 조정
- 에러 메시지 그대로 cpu 자원이 부족하여 kubelet이 파드를 스케줄링을 하지 못해 FailedScheduling 에러가 발생한 듯하다.
- 현재 노드풀은 다음과 같다.

- 노드에서 사용 가능한 자원을 확인해보자
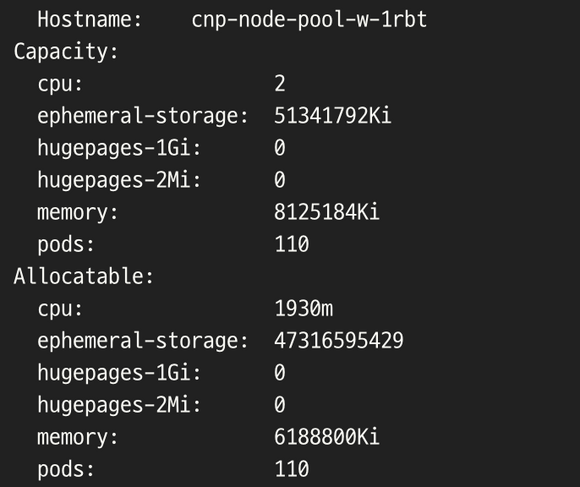
- kubectl describe nodes
- cnp-node-pool-w-1rbt 노드에 관한 테이블이다.
- 나머지 노드도 위 노드의 상태 테이블과 거의 일치하여 생략하였다.
- 위 node의 현재 상태의 정보를 살펴보면
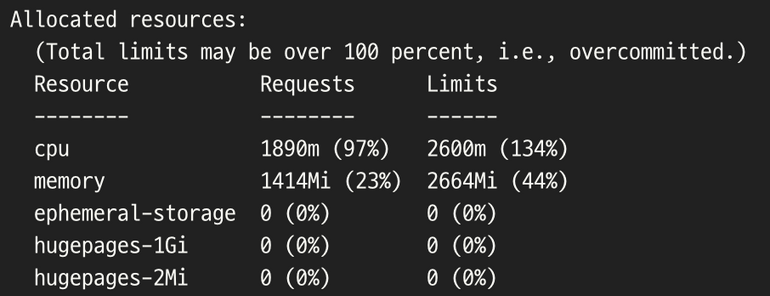
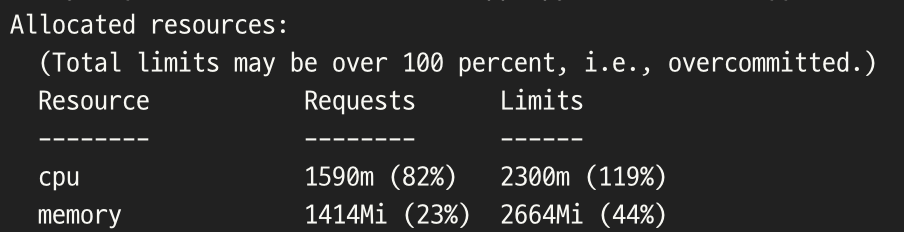
- 노드의 cpu 초기 용량은 2이며 할당 가능한 cpu 자원은 1930m의 양인 것을 확인할 수 있다.
- 그리고 현재 노드의 모든 리소스에 할당된 자원의 양의 합은 요청(Requests) 초기 값이 1890m인 97%, 제한(Limits) 값은 2600m인 134%을 확인하였다.
- 여기까지 보아 지금 노드안에서 할당할 수 있는 자원은 없는 것을 알 수 있고 그 Limits 자원 요청마저도 overcommited(과도한 할당)라는 것을 확인할 수 있다.
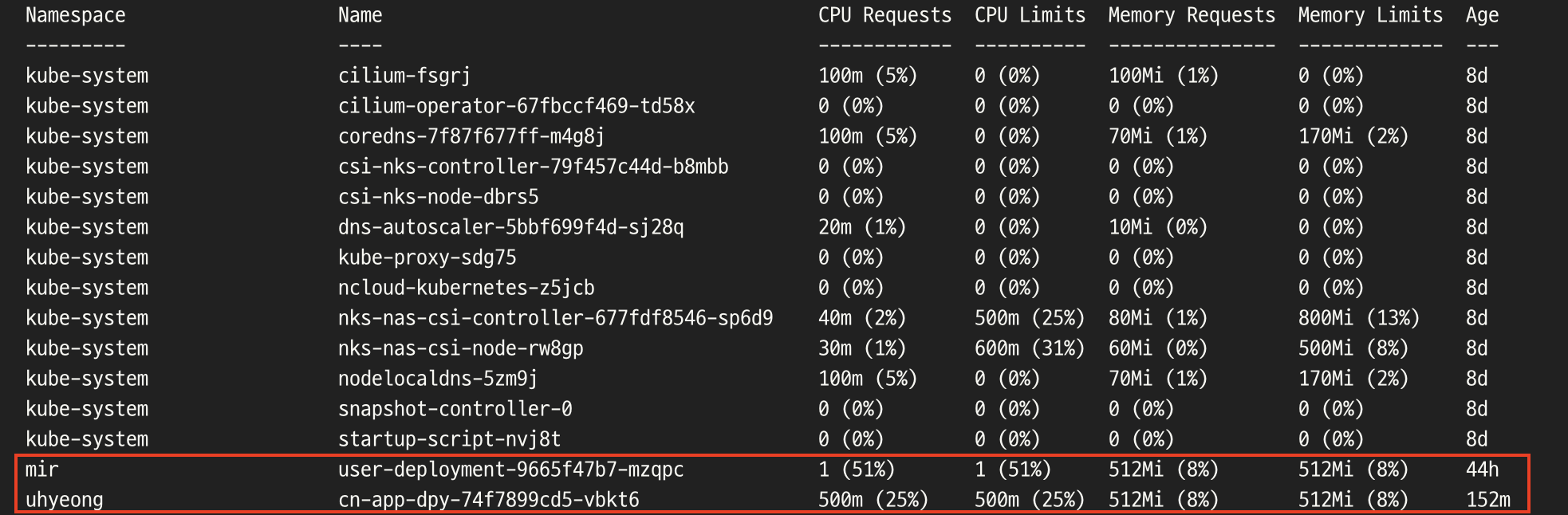
- 도대체 노드안에서 누가 범인인가 싶어서 확인해 보았더니 빨간 박스 안의 리소스가 으마으마한 cpu와 memory 자원을 할당 받은 것을 확인할 수 있다.
- 무려.. 51%.. 25%..
- 그럼 이제 위 문제의 리소스들이 정말 할당을 요청한 자원을 충분히 사용중인지 확인해보자 !
- 일단 노드의 자원 사용량은
- cpu 73m → 3%.. 벌써 감이 오기 시작한다

- mir 네임스페이스의 파드 자원 사용량을 확인하였다.
- 2m + 3m = 5m..

- uhyeong 네임스페이스의 파드 자원 사용량을 확인해보았다.
- 2m + 2m = 4m…

- 여기서 중간 결론을 얘기해보자면 현재 디플로이먼트로 배포한 파드에서 컨테이너는 배포시 요청 자원보다 터무니없이 적은 자원을 사용하고 있는 것을 확인할 수 있었다.
- 이는 파드 배포시 과도한 자원 요청으로 엄청난 자원 낭비를 보여주고 있는 중이라 말할 수 있다.
- 이제 해결해봅시다 !
- 배포시 사용한 매니페스트 파일 수정 후 적용
- kubectl edit deployment -n <namespace>로 deployment의 resources.cpu 내용 수정하였다.
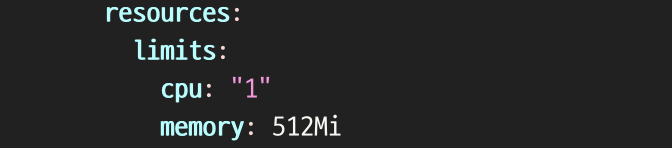
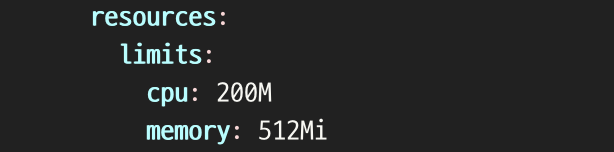
- 근데 또 뭔가 이상하다..
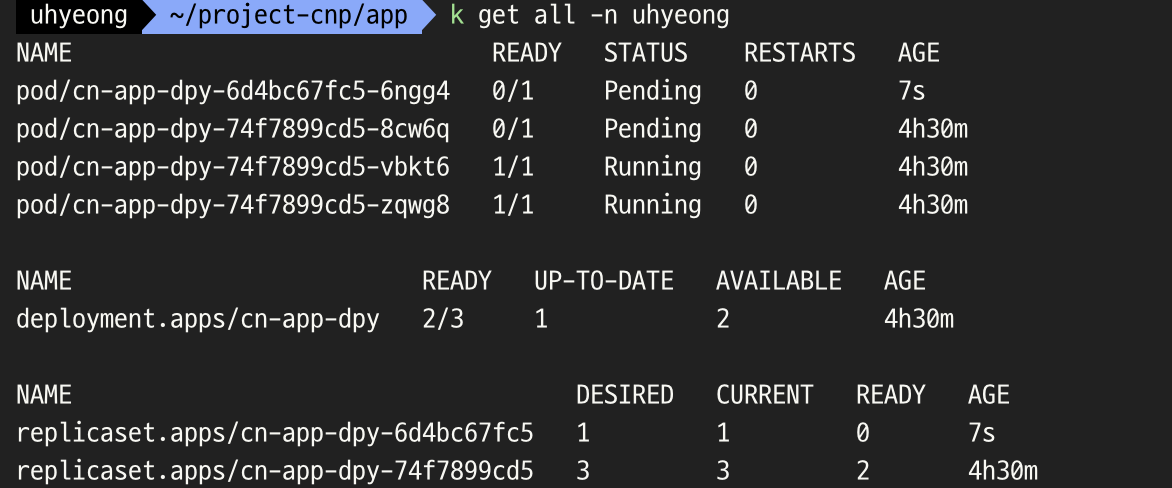
- rollout이 고착 상태..

- 스케일 업으로 수정된 버전인 새로운 파드 생성을 하다가 할당할 cpu 자원이 부족해서 고착되었다,,,
- 웃프다..

- 그럼 디플로이먼트의 매니페스트 수정으로 롤링 업데이트를 할 수 없다면 자원을 지웠다가 다시 배포하는 수 밖에 없는건가?
- 일단 임시방편으로 리소스 스펙을 완전 최소한의 자원으로 설정한 후 롤링 업데이트하는 방법
- 충분히 가능성 있는 방안이지만 너무 임시방편 느낌이 강하다고 생각한다.
- .spec.strategy.type==Recreate 에 대한 전략 적용으로 업데이트하는 방법
- RollingUpdate 외에 새로운 타입의 방안인 Recreate에 대해 알아보고 적용해보자 !
- 일단 임시방편으로 리소스 스펙을 완전 최소한의 자원으로 설정한 후 롤링 업데이트하는 방법
- ⭐️ 디플로이먼트 재생성 (type : Recreate)
- 기존의 모든 파드는 새 파드가 생성되기 전에 죽는다.
- 업그레이드 전에 파드 종료를 보장할 수 있다.
- 업그레이드 시 이전 버전의 모든 파드는 즉시 종료되며 신규 버전의 파드가 생성되기 전에 성공적으로 제거가 완료되기를 대기한다.
- 두구두구,, 수정을 해보자 !

- !!!! 뭔가 바뀐 것 같다 !!!!

- 흥분해서 여러 로그들을 다 확인해봤다ㅎㅎ
- Limits 자원 할당도 제대로 업데이트 확인
- 이전 버전 디플로이먼트의 Scale down 후 업데이트된 새로운 버전의 디플로이먼트 Scale up 확인
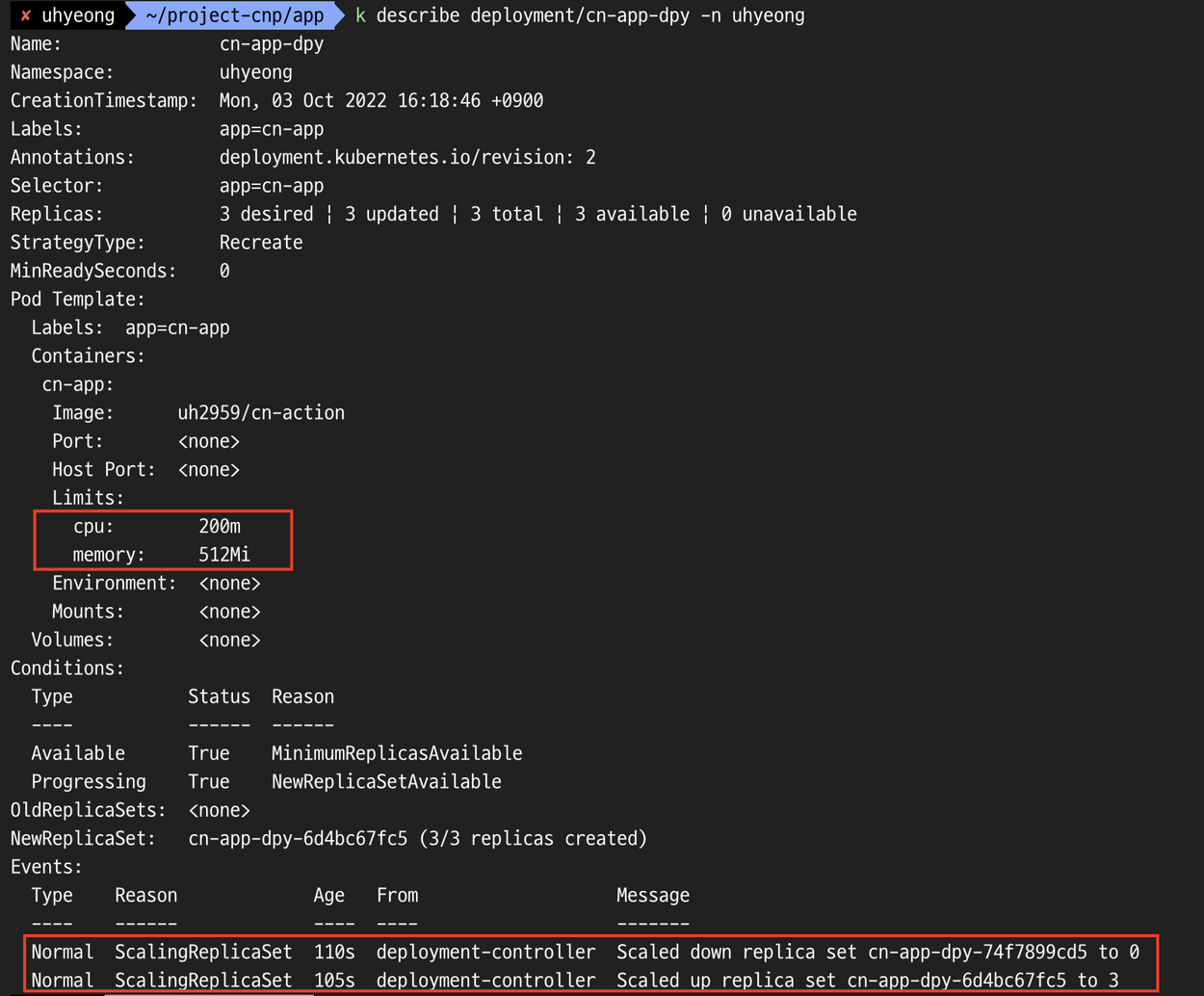
- 이전 버전의 파드 삭제 및 Scale down 후 Scale up에 대한 이벤트 로그도 확인
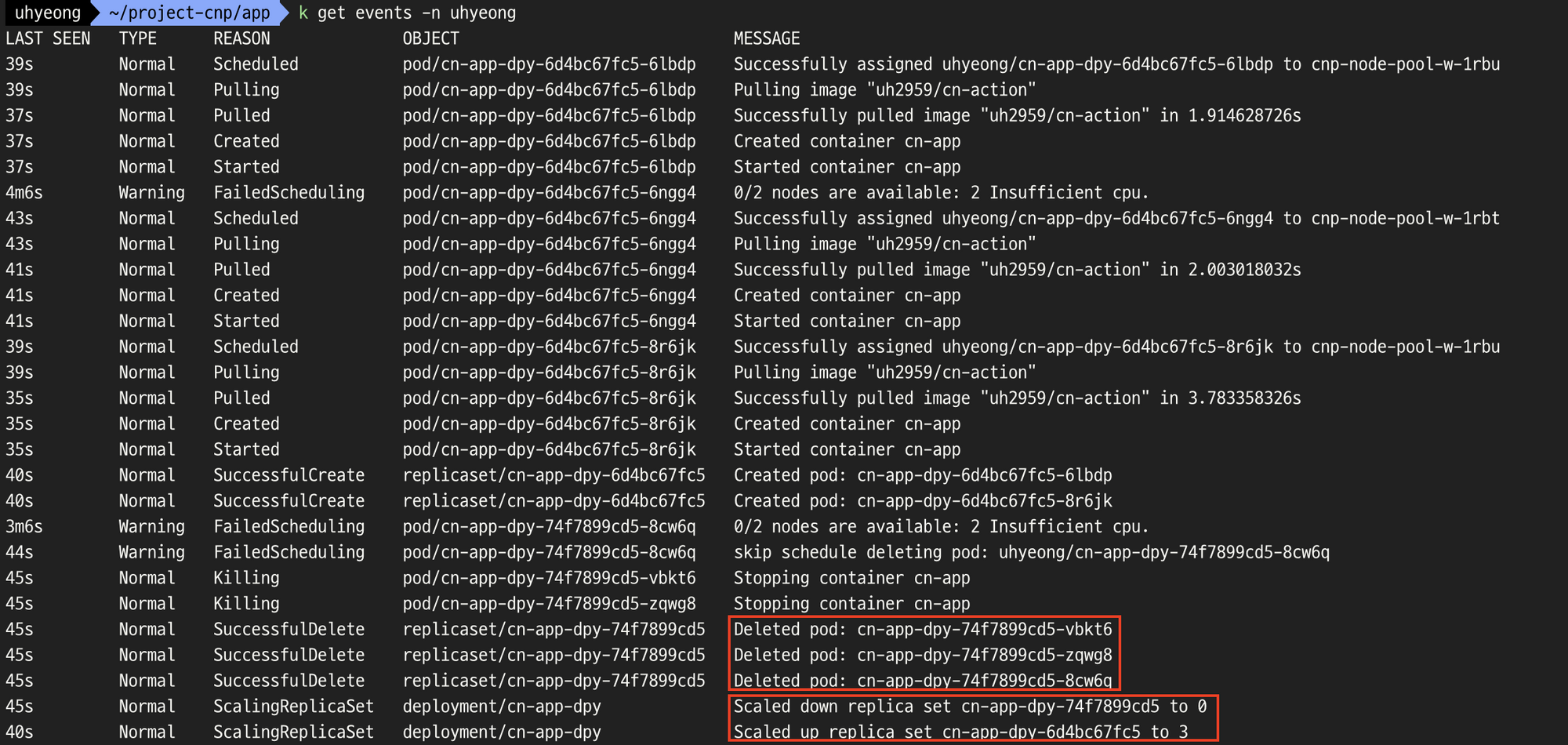
- 노드의 자원이 어느 정도 여유가 생긴것을 확인할 수 있다.
- 그럼 mir 네임스페이스의 자원은 일반적인 RollingUpdate type으로 업데이트를 진행해보자

- mir 네임스페이스의 디플로이먼트 매니페스트 파일 수정 후 롤링 업데이트 성공 !

- 이벤트 로그에서도 순차적으로 Scale Up 후 Scale Down에 대해 번갈아가면서 진행되는 것을 볼 수 있다.

- 노드 정보 확인
- 편안 ,,

⭐️ 결론
- 파드를 배포할 때 무자비하게 자원을 요청한 후 배포하면 나타날 수 있는 좋은 예시를 몸소 받았다..
- 하나 하나 고려해야할 점이 참 많구나.. 공부해야할 것이 늘었다는 이야기..
리소스의 메모리와 CPU 자원 관리
📍 Epilogue NCP의 NKS에서 프로젝트를 진행 중에 각자 팀원들에게 namespace를 할당해주었다. 어느 날 간단한 파드에 대한 스펙을 정해주고 생성을 시도하였더니 스케줄링 에러가 발생 원인을 확인해
code1212-uh.tistory.com
Pod 안전하게 생성/배포 및 QoS 정책 설정
📍 Epilogue 간단한 JAR 애플리케이션을 가지고 쿠버네티스 파드 배포를 시도하였다 ! 그런데 파드 상태가.. 엄청난 메모리 부족.. OOM Killed.. CrashLoopBackOff 상태 반복.. 파드 스펙 늘리고 다시 배포하
code1212-uh.tistory.com